株式会社はてなに入社しました
7 年目。老化のせいかコロナ禍のせいか、まだ 3-4 年目ぐらいの感覚である(何も成し遂げていない)
株式会社はてなに入社しました
7 年目。老化のせいかコロナ禍のせいか、まだ 3-4 年目ぐらいの感覚である(何も成し遂げていない)
この記事は はてなエンジニア Advent Calendar 2023 の 1/2 の記事です。昨日は ![]() id:nakataki の 1904年になりました(dayjsでの年入力の話) - nakatakiの日記 でした。190x 年から脱出できない面白い不具合でした。
id:nakataki の 1904年になりました(dayjsでの年入力の話) - nakatakiの日記 でした。190x 年から脱出できない面白い不具合でした。
「変化バジェット」という考え方があります。というか世の中には無いんですが、僕は社内でこの概念をよく使っています。
だいたい名前から想像するものと同じなんじゃないでしょうか。組織が変化に対して許容できる予算枠だったり、組織が変化に対して投資する予算枠だったりを指しています。
変化バジェットは、組織が効果的に変化を取り入れ、消化できる能力の範囲を指します。
組織の変化に許容量があるという概念は、組織に対してパッチを当てると言い換えると分かりやすいでしょう。小さな Pull Request ならすぐにレビュー&マージできますが、大きな PR は時間が掛かりますし、より多くの場所で障害が生じる可能性があります。
組織は、しばしば新しい変化に対して抵抗を示します。この抵抗は主に既存のプロセスへの馴れから来ています。
大きな変化を起こすと、その後一定期間は次の変化を起こせなくなります。新しい変化に体が馴染み、適応するために時間やエネルギーを使うからです。また、小さな変化を起こし続けていると、一定の力を変化への適応のために使い続けているため、目標達成のために全力を出せない状態になっているかもしれません。この状態だと大きな変化にも耐えられないでしょう。
チームが許容できない量の変化を持ち込むと、変化への適応をやりきれず、J カーブで成長していくつもりが、変化によって低下している期間が思った以上に長く続いて、アウトプットが下がります。
変化に適応するためには、組織が変化を取り入れ、消化できる能力の範囲、つまり「変化バジェット」を認識して変化を持ち込むことが必要なのです。
変化に許容量があるのはなんとなく分かると思うけど、許容量があるということは、これはリソースなので、戦略的に使い切りたい。
そもそも変化すべきであるというのは前提として良いでしょう。半年後に同じ生産性だと何も成長していない=市場についていけなくなるので、何かしら変化を持ち込む必要は、あります。
変化バジェットを十分に消化できなかった場合、組織は本来すべきだった成長機会を失っていると考えるのが望ましいと私は考えます。各メンバーのスキルアップやプロセスの最適化、新しい技術の採用、とかの具体例を想像すると、消化していないと長期的に影響があることが分かりやすいんじゃないでしょうか。プロダクト開発のロードマップと突き合わせて、どのタイミングでどんな変化を持ち込むかを考えましょう。
また、変化バジェットは人間の感覚的な抵抗なので、基礎変化量からの比で表せることにも注目しましょう。ウェーバーの法則ですね。この法則は、基本的な刺激量からの相対的な比率で刺激を知覚することを示しています。
たとえば、100の刺激が110になったときはじめて「増加した」と気付くならば、200の刺激が210に増加しても気付かず、気付かせるためには220にする必要がある。
変化に慣れていない組織では、わずかな変化 (例えば100から110への増加) が顕著に感じられ、適応リソースを払うべきものになりますが、変化に慣れている組織では同じ変化量と感じるためには、より大きな変化 (200から220への増加) が必要になります。これは、日常的に多くの変化を乗りこなしている組織だと、小さな変化には適応リソースを少なく、より大きな変化に対しても適応しやすくなることを意味します。
変化バジェットを未使用のまま放置すると、組織は変化しない状態を「新たな標準」と見なし始める可能性があります。SRE におけるエラーバジェットと同じですね。安定への期待が過度に高くなり、変化への対応能力が低下するリスクがあります。
逆に変化バジェットを積極的に使っていくと、変化することが当然となっていくので、変化バジェットは徐々に増えていきます。
組織変革 (Change Management) において、変化バジェットという考え方を書いてみました。
組織には、変化を受け入れられる許容量があり、これを「変化バジェット」として考えることができます。変化バジェットをリソースとして適切に計画し管理することで、組織の適応性や成長を高めていくことができます。
変化バジェットは感覚的な要素を含み、馴れによって容量が拡大することがあります。つまり継続的に小さな変化を導入することで、変化に対する耐性の高い、強い組織を作れます。変化バジェットの小さいところでは、無理に大きな変化を起こすのではなく、小さな変化から始めることが有効です。
精神的なものだけじゃなく、仕組みによっても拡大します。アジャイルなマインドセットや、イテレーションごとのふりかえりが機能している、チームの生産性を定量・定性的に観測しているチームは、絶えず変化と適応を繰り返しているので、変化バジェットが大きくなりがちですね。また、小さな変化だけでなく、狙いを持った大きな変化を定期的に持ち込むというのも効果がありそうです。組織体制を変えるとかですね。
はてなエンジニア Advent Calendar 2023、まだ続いていきそうです。
*1:日付を絞っているのは PHPカンファレンス福岡2023に proposal を出した から。
これは はてなエンジニア Advent Calendar 2023 の 18 日目の記事です。昨日は ![]() id:gurrium による private-isuで70万点取るためにやったこと - ぜのぜ でした。私は 50 万点ぐらいで満足してしまっていたので、しっかり詰めていて凄いなと思う。
id:gurrium による private-isuで70万点取るためにやったこと - ぜのぜ でした。私は 50 万点ぐらいで満足してしまっていたので、しっかり詰めていて凄いなと思う。
Web アプリケーション開発において、「キャッシュは麻薬」という言葉がインターネット上をよく飛び交っています。YAPC::Kansai OSAKA 2017 の ![]() id:moznion のトークでよく知られるようになったワードじゃないかな。
id:moznion のトークでよく知られるようになったワードじゃないかな。
初出はちゃんとは分からないんですが、少なくとも 2011 年には言われていますね。
「キャッシュは麻薬」とはよく言ったものだ。
— TOYAMA Nao (@nanto_vi) November 5, 2011
キャッシュに頼ると即時的にパフォーマンスが解決する。この即時効果に魅了されてしまい、根本的なパフォーマンス問題を覆い隠したままキャッシュに依存するようになり、そして脱出するのが難しい、という性質をよく表している言葉です。ですが、本当にキャッシュに依存するのは間違っているんでしょうか。
「キャッシュは麻薬」という言葉により「キャッシュ=使うべきではない」と思考停止してしまう、しまっているのではないか。十把一絡げに「麻薬」と言うのではなく、キャッシュをパターン化して乗りこなすというのが望ましい姿でしょう。現代的な Web アプリケーション開発において、キャッシュを使うのはむしろ前提としないと機能しないと私は考えます。
パターン化は moznion の発表でもされていたんだけど、私の目線からも分類してみます。
レスポンスをまるっと CDN 等でキャッシュしてしまうパターン。現代の Web アプリケーションでは基本的に CDN は挟む前提でしょうから、これはもちろん許容されているキャッシュでしょう。
ありがちな失敗として、認証が必要なページをキャッシュしてしまうというのがある。また、PC とスマホとで出し分けるときなど、CDN のキャッシュキーとアプリケーションの出し分け条件が異なっていて、違う環境向けのコンテンツをキャッシュしてしまうミスも時々発生している。
一度キャッシュしてしまったらアプリケーションの制御下よりも手前で返してしまうため、キャッシュのパージがそこそこ難しい。
べき等な、副作用の無い処理ならキャッシュ可能という考え方で扱うんだけど、副作用のあるリクエストでも Idempotency-Key Header を利用して高速にレスポンスを返すパターンもある。これはクライアントからのリトライ時に使います。
サーバー側があったので、クライアント側も書いておく。自分が受け取ったレスポンスを保存(キャッシュ)しておくのは、速度以外だと主に以下の目的です。
リクエストを投げすぎないようにするためには、最終取得日時を持って、比較しながらリクエストを投げれば良い。Squid 等の proxy や、 unique 制限付きの request queue (同じ URL に対する queue は 1 つにマージする的な) で対応することも多そう。
リクエスト先が落ちていてもキャッシュからどうにかするのは、SWR 的な考え方ですね。「stale でも緊急時に使って良いキャッシュ」というのはある。
Rails Guide に書いてある程度には一般的なキャッシュ。belongs_to にオプションを追加するだけという、非常に手を出しやすいモデリングがされているので、これも使って良いキャッシュだろう。
例えば Entry -> Comment という関連があるときに、entries テーブルに comments_count カラムを持って、コメントが作られる/削除されるたびに comments_count カラムを更新する。
このように「子の要素数を親に持っておく」のは非常に一般的な要件だと思うんだけど、カウンターキャッシュ以外に名前付いているんですかね?このパターンの名前を他に聞かないなと思っている。
ところで Rails でカウンターキャッシュを実現するときに、ActiveRecord に組み込みのものと、より柔軟に扱える counter_culture gem とがあります。counter_culture はコード読むのとてもオススメです。README だけでも「カウンターキャッシュ」にだいぶ色んな要件があるのが分かって面白いと思う。
どう言えばいいのか分かんなくてパターン名を付けられていない。イメージはカウンターキャシュと同じ。ただカウンターキャッシュがカウンターに特化しているのと比べ、必要なデータを必要な形に加工して保存しておくというのが特徴。
例えば Markdown で書いたブログの HTML Body がこのパターンに当たる。マスタとなるデータを更新するときに、一緒に or 非同期でキャッシュデータを生成する。
アクセス数ランキングもそうですね。アクセスログというイベントデータと、その加工先としての本日のアクセス数ランキング。ランキング表示時にアクセスログを毎回舐めたりはせず、事前に集計しておいた、引きやすい形に加工したものを持っているはずです。
アクセス数ランキングを想像すると、イベントソーシングの考え方とも近しい存在であるというのが分かると思います。イベントを全てアプライしたリソースは、仮に失ってもイベントから再生成できるので、キャッシュのようなものですね。
このパターンの場合、今見ているキャッシュはどこまでをアプライしたものなのかが分かりづらくなるんですが、同期的に扱えていればこの悩みとは無縁です。なのでトランザクションを持つデータストアで、マスタデータとキャッシュとを同じデータストアで扱うと楽になります。そうでない場合は、頑張りましょう。(実装パターンは幾つかあるんだけど、余白が足りない)
HTML のパーツ単位でキャッシュする。これも Rails ガイドにありますね。
レンダリング時にキャッシュがあれば使う、なければキャッシュを作る、という動きをする。具体的には以下のようなコード。
<% @entries.each do |entry| %> <% cache entry do %> <%= render entry %> <% end %> <% end %>
これは entry を render したものを、entry の id と updated_at をキーとしてキャッシュしている。updated_at がキーに含まれているので、更新するとキャッシュキーが変わる=キャッシュミスとなり、更新された新しいコンテンツで描画される。(実際はもっと複雑なことをしているけど、概要としては合ってるはず)
View やシリアライザでキャッシュするという考え方なので、HTML を離れて JSON API となっても活用することはできる。
ところで開発が活発な(?)アプリケーションでのフラグメントキャッシュでは、コンテンツの更新とテンプレートの更新との両方がキャッシュに影響します。Rails の場合はキャッシュキーにテンプレートの digest が入るようになりました(Rails 4 からなので 10 年前ですね)。このおかげで、コンテンツの更新だけを考えれば良くなっている。
Webアプリケーションのキャッシュ戦略とそのパターン で言うところの Broker パターン。Primary なデータストアにアクセスする前に 必ず 通るキャッシュ。
透過的なので実装時に認識しづらく、デバッグも割と困難なため、あまり導入するべきではないが、ここぞと言うときに入れるとバグも少なく負荷が軽減される。ミドルウェアを挟むだけで実現できるのもまさしくいざというときに効く。
最初から設計していないとリロードするまで最新情報が表示されない等の副作用も出るので、いきなり導入するのは非常時の手段。
Read Through Cache、Write Through Cache と呼ばれることもあり、読み込み時のみならず、書き込み時も Broker を介して書き込む場合もある。これをやると書き込み直後のキャッシュが必ず最新を保てるが、常にダブルライトするのは無駄になることも多い。
Broker ではないが、データストアのレプリケーションを利用しての Read/Write Splitting も特徴がかなり似たキャッシュ形態だろう。Read/Write Splitting も飛び道具として機能することが多い。
レプリケーションであれば、「普段は replica 向きの connection を使う。保存系のクエリは primary に向け、そのリクエストの続き or そのユーザの数秒以内のリクエストでは読み込み系のクエリでも primary 向きの connection を使う」のような connection pooling の仕組みがあると、副作用を最小限にしていい感じに扱えるかもしれない。Rails の複数 DB はよくできているので、こちらもコードを読むのをオススメします。
これが賛否両論あるヤツで、いわゆる麻薬です。下手に入れると本当に困る。
キャッシュ アサイド パターン - Azure Architecture Center | Microsoft Learn と言われる。
Caching Strategies and How to Choose the Right One | CodeAhoy や Webアプリケーションにおける正しいキャッシュ戦略 - Sansan Tech Blog でも同じ名前が当てられていますね。
アプリケーションコード内のあらゆる箇所でこの制御を入れようとすれば、あっという間にカオスになります。
が本当にそうなので、このパターンを使用するときは被害を最小限に食い止める設計と一緒じゃないと死です。無計画にやっていると、50 個を越えた辺りから不吉な臭いが漂ってくるだろう。この辺りから意図せず多段キャッシュになってしまい、どこのキャッシュをパージし忘れているせいでデータが更新されないのかを追えなくなっていく。
HTTP キャッシュは Web配信の技術 にすべてが書いてある。
また、フロントエンドのキャッシュもいっぱい話題はある(Apollo Client のキャッシュとか、Next.js のキャッシュとか。それぞれで 30 分トークができちゃう)んだけど、僕があんまり専門じゃないので他の人にお任せします。
ところでユーザリクエスト起因でキャッシュしているとキャッシュパージ時に非常に困るという話を以前したので、こちらも参考にどうぞ。
このエントリの骨格は YAPC::Hiroshima 2024 に CfP を出した ものでしたが、なんと前夜祭で、![]() id:Soudai さんと一緒に話すことになりました。ここまでを下敷きとして、更に深い話をします。
id:Soudai さんと一緒に話すことになりました。ここまでを下敷きとして、更に深い話をします。
YAPC::Hiroshima 2024 前夜祭のキャッシュバスターズ、いったい何者なんだ…… #yapcjapan pic.twitter.com/osdBMFACKj
— Takafumi ONAKA (@onk) October 24, 2023
まだチケットを購入可能なので、ぜひ来てください。
YAPC::Hiroshima 2024のチケットは本日までの販売予定でしたが、発売終了日を2024年1月10日(水)に変更しております。参加するかどうか悩めるのはあと1ヶ月、「行くぞ!」と決断したら、忘れずにチケットをご購入くださいね! #yapcjapanhttps://t.co/L4ds6JsIjz
— yapcjapan (@yapcjapan) December 15, 2023
キャッシュは麻薬と言われていますが、絶対に避けなければいけないものではありません。整合性が壊れやすくなることが問題なのです。そこでキャッシュの幾つかを分類し、これは使っても良いキャッシュであろうというパターンを挙げました。また、使うと後世で困りがちなキャッシュについて、気を付けるポイント(主にキャッシュアサイドパターンで多段キャッシュになるのが問題である)を書いてみました。
\キャッシュと上手に付き合おう!/
はてな Advent Calendar 2023、明日は ![]() id:tokizuoh さんです。
id:tokizuoh さんです。
この記事は Mackerel Advent Calendar 2023 の12月1日の記事です。トップバッターいただきます。
Mackerel チームでエンジニアリングマネージャーをやっている id:onk です。最近は特に OpenTelemetry 対応を進めているチームのそばにいます。
個人で Mackerel をどう使っているかの一部をチラ見せします。
まずはこのダッシュボードを見てくれ。
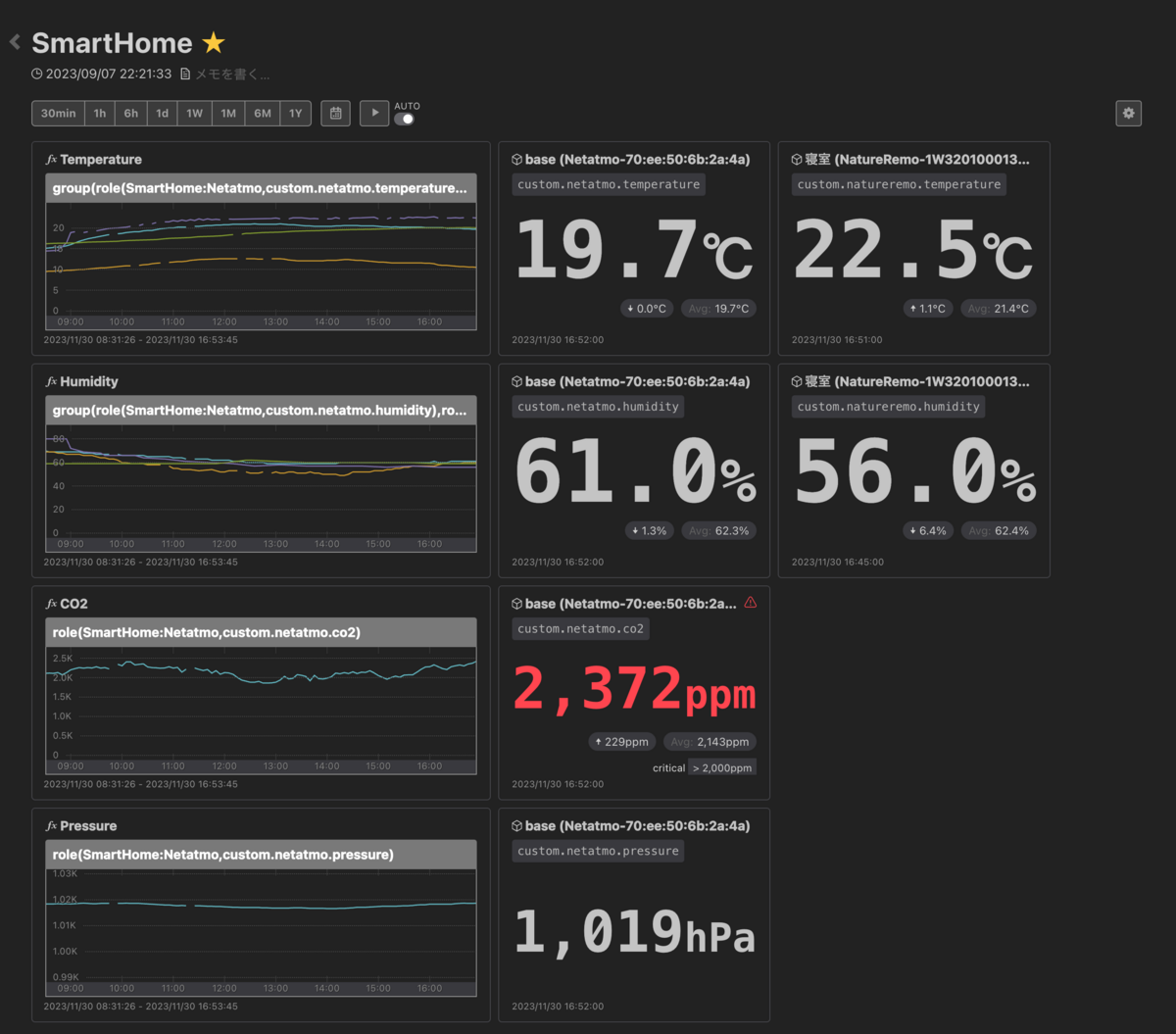
リモートワークになってから快適に暮らすために、気温、室温、二酸化炭素濃度、気圧なんかを測って投稿している。二酸化炭素濃度が上がるとアラートを鳴らして換気するなどのアクションを取りたいし、気圧が急激に下がるときは頭痛ーるのようにアラートを投げたい。というわけで Nature Remo や Netatmo を利用して測定しています。
測っている値は 3 年前から特に変わっていないんだけど、その間にダッシュボード側が進化したのでそれぞれ紹介していく。
僕は数値ウィジェットの隣にグラフを置いて「上がっているか下がっているか」を把握しやすいようにというダッシュボードを作っていたんだけれど、数値ウィジェット単体でも把握しやすくなった。

数値ウィジェット内に「↑」「↓」が表示されるようになったので、グラフと並べずに、数値だけで上昇傾向か下降傾向かを判断し得る。例えばこうして上段に数値ウィジェットだけをまとめて、高さ当たりの情報量を増やすことが可能かもしれない。
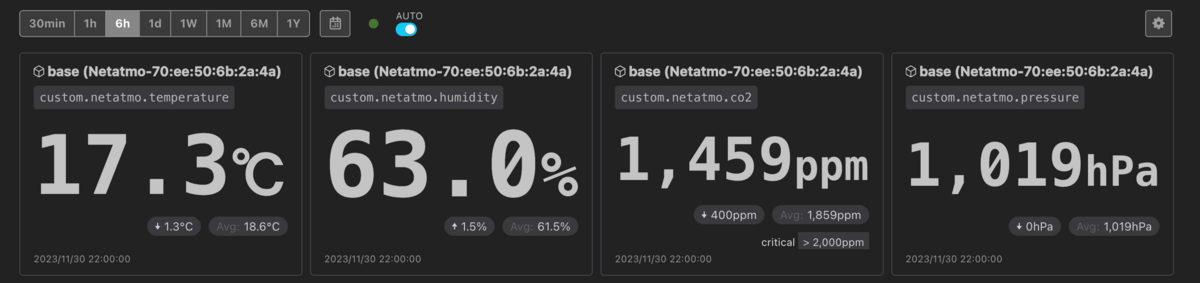
この機能は はてなリモートインターンシップ2023 で ![]() id:laminne さん
id:laminne さん ![]() id:ucciqun さんが開発してくれました。メンターを担当した
id:ucciqun さんが開発してくれました。メンターを担当した ![]() id:mds_boy さん
id:mds_boy さん ![]() id:rmatsuoka さん、機能を提案した
id:rmatsuoka さん、機能を提案した ![]() id:heleeen さん、デザインした
id:heleeen さん、デザインした ![]() id:issan883 さん、お疲れさまです!
id:issan883 さん、お疲れさまです!
ダッシュボードを一目見ただけで健康かどうかを把握したい。二酸化炭素濃度は分かりやすくアラートの基準としているので、そのものズバリで Critical な見た目になるようにしました。
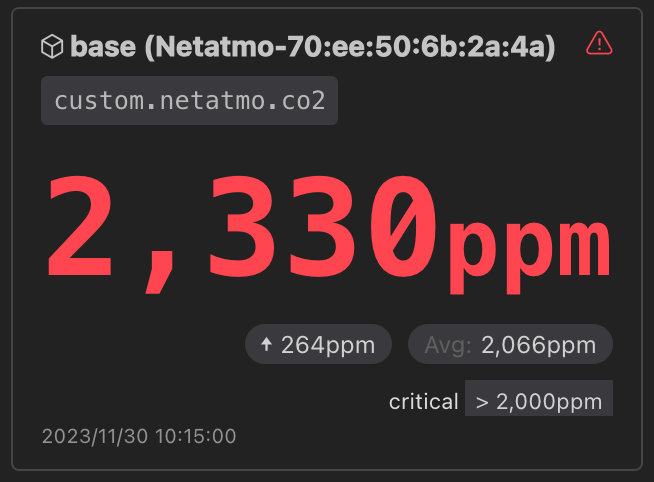
ダッシュボードを見たときに「オッ」となるので便利です。業務でもアラートが鳴る -> ダッシュボードを見る -> ヤバいところが目立っている、という体験ができます。
![]() id:azukiazusa さん
id:azukiazusa さん ![]() id:inommm さん
id:inommm さん ![]() id:issan883 さん
id:issan883 さん ![]() id:mechairoi さん、機能を提案した
id:mechairoi さん、機能を提案した ![]() id:arthur-1 さん、お疲れさまです!
id:arthur-1 さん、お疲れさまです!
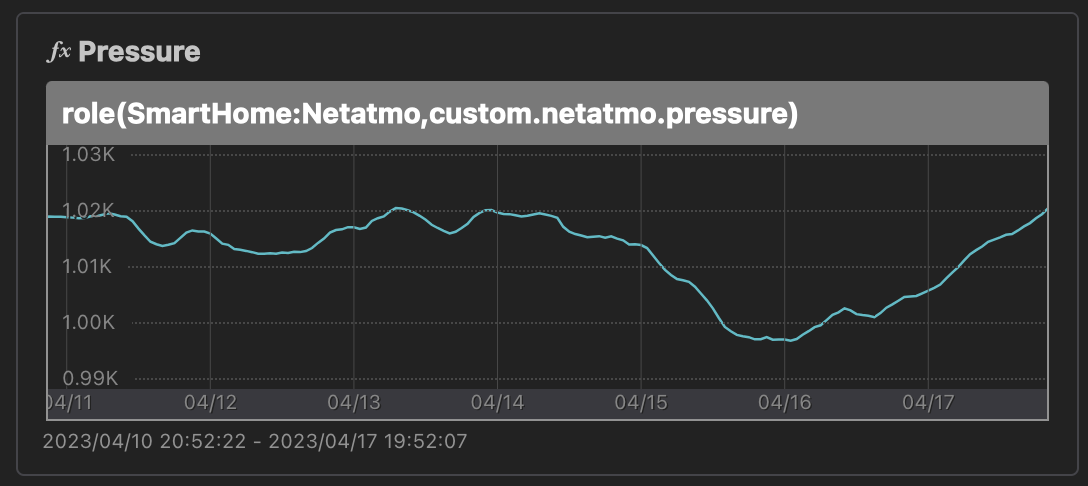
気圧のグラフですが、気圧は 990hPa〜1030hPa ぐらいの値を取るため、何も工夫せずにグラフにすると、増減がまったく分からないグラフになります。
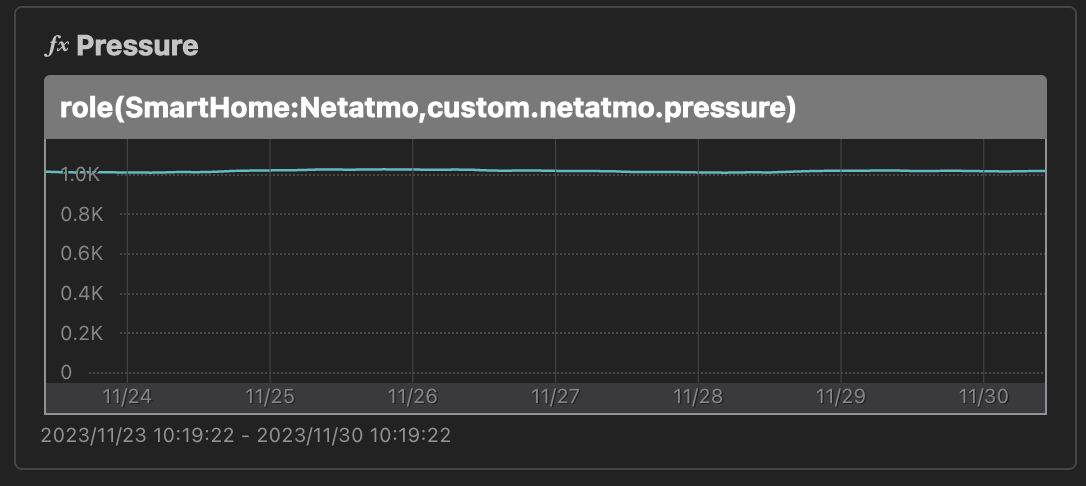
これを避けるために offset(..., -1000) して表示していました。-990 ぐらいにしておかないと台風の日なんかにマイナスになるんですが、グラフの縦軸の数字の分かりやすさを優先してしまった。。
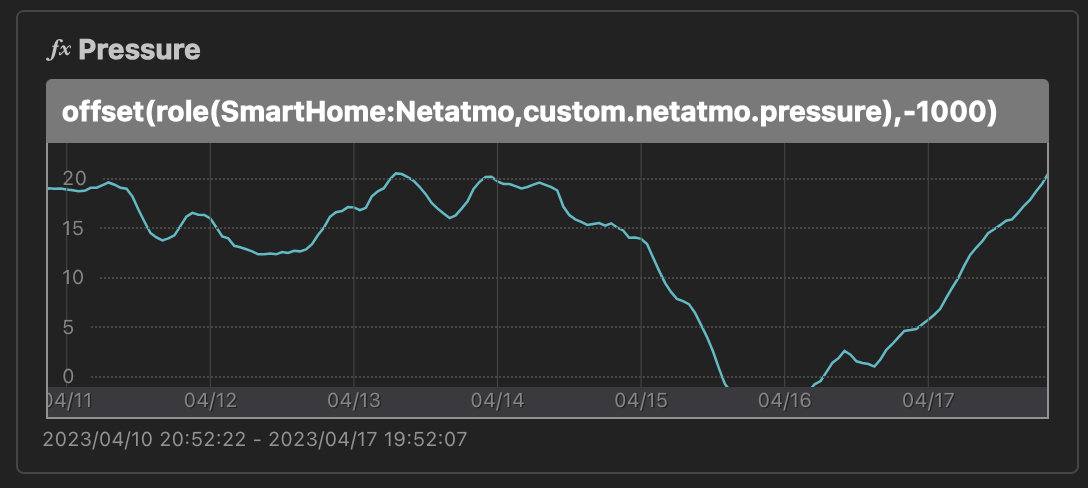
グラフ縦軸固定機能が入ったので、offset で頑張らなくても自然に表示できるようになりました。
![]() id:arthur-1 さん
id:arthur-1 さん ![]() id:yohfee さん、お疲れさまです!
id:yohfee さん、お疲れさまです!
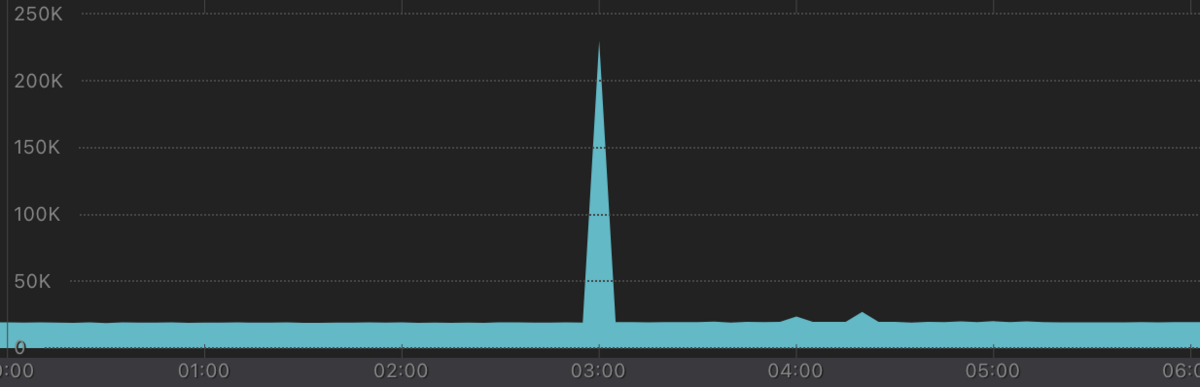
実務では、このように足切りしたいようなグラフや、稀にスパイクが起きるようなグラフで使って貰うと良いのかなと思います。上限を遙かに突破されると、しばらく変化が見づらくなるので。
このように、カスタムダッシュボードには色んな機能が最近 (今日紹介したのはそれぞれ今年開発されたものです) 増えているので、より直感的に把握できるダッシュボードになるようカスタマイズしてみてください。
Mackerel Advent Calendar 2023、明日 2 日目は ![]() id:rmatsuoka さんです。
id:rmatsuoka さんです。
書かなければいけない宣伝。こうした機能を提案、実装した 開発者に会いに行けるサービス である Mackerel は、12/19 (火) に Mackerel Meetup #15 を開催します。
「チームとコミュニティで監視を育てる」をテーマに、監視を育てるスタート地点でもあり、考え方でもある「SRE」の概念やその導入方法、具体的な実装について知ることのできるコンテンツを用意しています。明日から自分たちの監視やシステムを育てるヒントにしていただけたら幸いです。今時点で Mackerel を使っていない方でもぜひご来場ください!
詳細とご応募はこちらから!
いつものメンバーで参加した。このメンバーで組んだのは ISUCON9 からなので、もう 5 年になるのかー
東京、京都、シアトルと、全チームの中でも地理的にはかなり離れているチームなんじゃないかな。
今回は僕がインフラ担当。3 人ともどこでも担当できるのは面白いメンバーだと思う。
最終スコアは 39,560 で、https://isucon.net/archives/57993937.html を見る限りは 40 位っぽい。再起動試験を含まないポータルのランクでは 49 位。

素振りは 2023/9/10 (12予選) と 2023-11-04 (11本選) の 2 回やった。本番と同じ形で、8h 一本勝負。どちらもそこそこの点(本選出場チームの真ん中ぐらい)は取れたので、そのぐらいはいけるんじゃないかという感覚。
素振った結果として、僕の時間の使い方は以下で行こうと決めていた。
また、EC2 はとりあえず 6 台立てて好きに使えるサーバを増やしておこうという話をした。
という理由。
リポジトリは公開している。https://github.com/onk/isucon13
リポジトリ作って撒く。rust/target 以下が .gitignore されていなくてイラついたけど、ちょっと待ったら git add できたのでそのままコミット
入っているミドルウェア等を把握して、いつもの conf を適用。
あとで分かったけど、ここで静的ファイルにキャッシュ入れてたわ。私が戦犯です。
alp、pt-query-digest 取得
この時点では「icon を静的化しよう」「statistics はどうにかする必要がありそう」「あとは INDEX 張ってから考える」までしか僕は分かってない。
INDEX 足すねー、と言って足す。最速でできたと思う。
やったのは ruby/app.rb から SQL っぽいものを抜き出して、眺めながら WHERE 句と ORDER BY 句に入っているものを愚直に index にしただけです。まだアプリは何も読んでないが INDEX だけなら勘でできる。
例えば
SELECT * FROM livecomments WHERE livestream_id = ? ORDER BY created_at DESC
を見たら
alter table livecomments add index livestream_id_and_created_at (livestream_id, created_at desc)
と書く感じ。この作業は機械でできそう。
pprof 取得して会話
という話をしたはず?
ADMIN PREPARE が出ないように interpolateParams=true に
デプロイ周りの整備したり複数台構成にする準備をしたり
明らかに MySQL が 100% 食っているので、アプリが使うデータストアを分離。
N+1 倒したら redis 置く隙ぐらいあるだろうと思って適当に。
statistics は redis に sorted set でランキングを持つ、各値も redis に持つ。pt-query-digest も pprof もコレだと言っているので、これはやる。
icon 静的化にここまでかかった……。try_files でデフォルトアイコンを出す?ユーザが無いときは 404 にしなきゃいけないんじゃない?みたいなので途中で作戦変更することになった。
結局、初期ユーザは NoImage.jpg を置いておく (initialize でコピーする)、register 時にも NoImage を置く、アイコン変更 (postIconHandler) 時に静的に書き出す、とした。icon はこれで静的に返せるので、あとはまるっと nginx 任せ。
なお If-None-Match の件は僕はマニュアル読んでなくて気づいてない。
Tag を redis に cache をデプロイ (2h 前に完成していたのでさっさと入れたかったね……)
fillLivestreamResponse の N+1 が潰れる。tags も DB から外して redis にのみ持つようになったはず?
pprof に出ていた moderateHandler を潰す。NGWord のループが潰れて、謎の DELETE 文は素直になった。
alp に出ていた GET reaction と GET livecomment の N+1 を潰そうとするが解決に時間が掛かる。結局最後に revert。
そしてベンチはひたすら「新たに設定したアイコンが反映されていません」と言ってくる。謎。
redis 化していた getLivestreamStatisticsHandler を、もうベンチ全然通らないしとエイヤでマージ
今回 fail で終了だー、と自棄になりつつとにかく enqueue しまくる
なぜか最終点がベストスコアで出ている
作戦はまぁミスってない、とにかく手が遅い!!!
インフラ的にも酷い感じだった。
あと isudns にインデックス張ってないのを眺めに行ったにも関わらず見逃したのも酷かった。追試した感じこれは大差なかったですが。
2 人で 1 つをやらずに別の N+1 を潰しに行っていたら多分あと 2-3 手はやれたなーと思っていて、30 位は普通に行けましたね。。 matsuu/aws-isucon で追試したら 2 台構成のままでも N+1 2 つ潰しただけで 50,000 点が出たので本当にアプリ側書く手の早さだなーと思う。そして nginx の config は本当にベンチの不安定さに繋がっていたので戦犯。
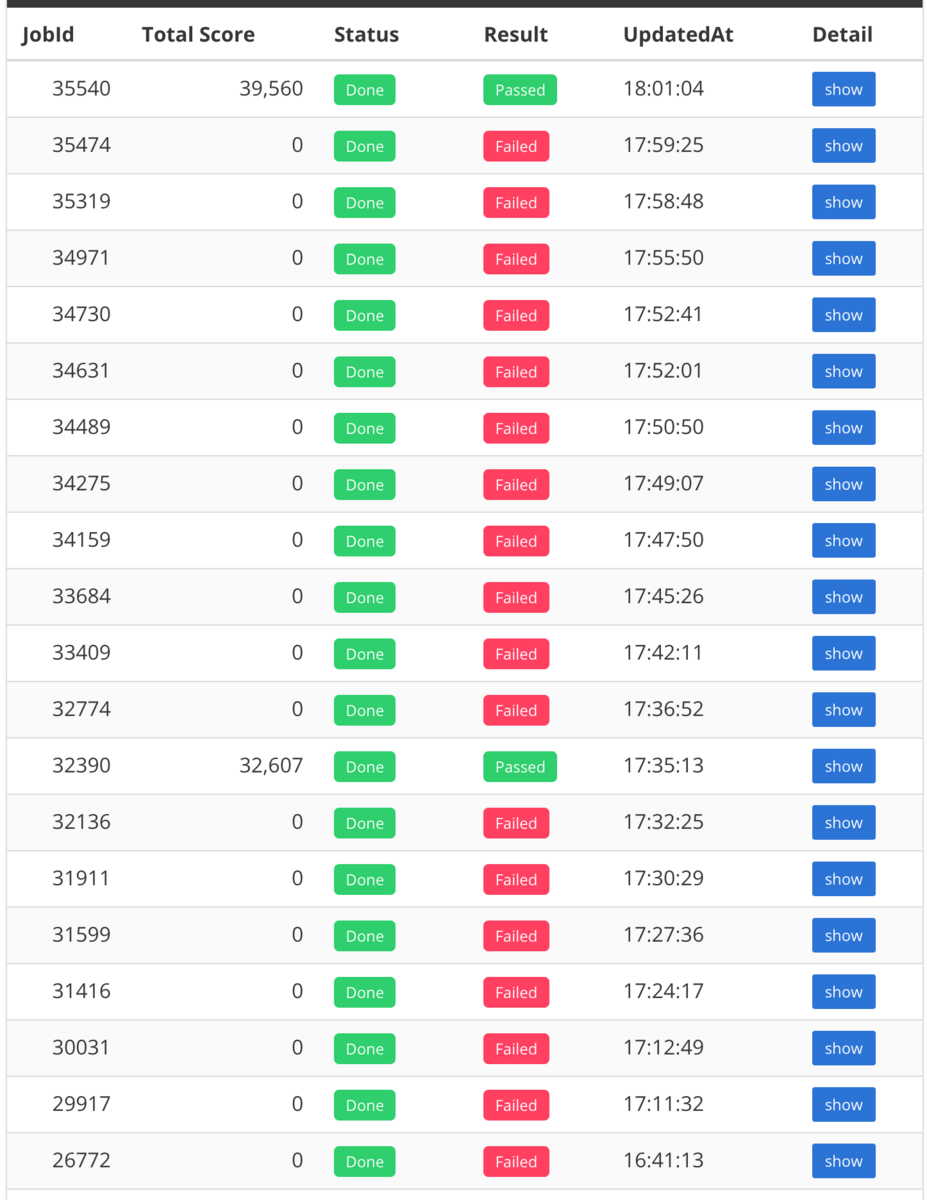
よく最終点出たよね。運が良すぎると思う。
反省の残る回だった。来年また来ます。
1 年ぶりに本番に出た感想としては、練習ではベンチを任意のサーバに対して流し放題なのに対して本番では制限があるので、ベンチを流す回数が圧倒的に少なくなるなと思いました。開発のリズムがまったく違うので、本番相当で練習した方がヨサソウです。
ベンチを流す前に、
env.sh で ISUCON13_POWERDNS_SUBDOMAIN_ADDRESS を ベンチ対象の IP アドレス に向ける./webapp/pdns/init_zone.sh して *.u.isucon.local を ベンチ対象の IP アドレス に向けるで、ベンチ実行は
$ ./bench run --enable-ssl --nameserver ベンチ対象のIPアドレス --webapp ベンチ対象のIPアドレス
です。
「次の職場が Ruby なんだけど」と読み書きそろばんを聞かれたのと、大阪Ruby会議03、大江戸Ruby会議10、Kaigi on Rails 2023 と Ruby/Rails 関係のイベントに続けて参加して、作者の皆さまと会ったので。
言語仕様は何らかの本 1 冊の冒頭の方を読めば雰囲気は掴めるだろう。
Ginza Rails27 igaiga - Speaker Deck
著書や技術顧問、健康診断レポート でお馴染みの @igaiga555 さんの作った表で、難易度別にまとまっている。
たのしいRuby か、プロを目指す人のためのRuby入門 が定番かなぁ。
は読んでいて面白いのでオススメです。まずはサラッと目を通す感じ。
Rails で何かアプリを作る。まず 1 個ぐらいは手を動かしておきたいね。
作るものが思いつかなかったら、Rails Girls のガイドを見ながら画像アップロード機能のある Web アプリを作ったり、Rails チュートリアル をやったりすると良いんじゃないか。
チュートリアルは長いので、サクッと rails new してナルホドと言えるぐらいのサイズで良い。
「何か gem があるんじゃないかと疑う」を基本行動としながらしばらく暮らす。
The Ruby Toolbox は昔からあるサイトなので、かなり古いメンテされていない (2010 ぐらいが最終更新の) ライブラリも載っている。古いのは見なかったことにしつつ、一番有名なのを触ると良いです。基本的に困るまでは有名どころしか使わなくても生きていける。
awesome-ruby はいつもの awesome- シリーズです。ちゃんとメンテされている(感謝)
アプリを作ったら dependabot や renovate でバージョンアップの指示があるたびに中を読みながら上げていくのも良いですね。現在進行形で開発されている現場の空気が分かっていくので。
Real World Rails にある各アプリの Gemfile を読むのも効いてきます。これも世界の現場感が身に付いていく。
こういう「gem を読む」を自然にやるためには、gem-src と ghq を入れておくのがオススメです。自分のアプリと gem との距離感がどんどん減っていって「読むのがふつう」になっていきます。
Enumerable や ActiveSupport の core/ext でできることを知って、代表的な gem が分かっていたら、ほぼコードの読み書きする分には困らなくなっていると思う。
辺りが次の話題かな。
まさに Kaigi on Rails はこういった話題を取り扱っているのでぜひ見て欲しい。
他は
とかになるんじゃないか。
あとは技術的な興味をどこまで持ち続けられるかみたいな勝負になる。新しい話題が次々飛び込んでくるように自分のアンテナをしっかり張っておきましょう。
ancestors を見るキッカケになるんじゃないか自分がこうありたいというメモ。
作業者と開発者の違いとして、問題解決への寄与だとか、創意工夫の余地があるかというのがありそう。
これは今 GPT-4 に聞いた。
Q: 作業者と開発者の違いを100文字ぐらいで教えて。
A: 作業者は指定されたタスクや手順を実行する人を指し、特定のルーチンや手順に従って作業を進めることが主な役割です。一方、開発者は新しい製品やソフトウェアを設計・構築する人を指し、創造性や技術的なスキルが求められます。作業者は指示に従い行動し、開発者は新しいアイディアや解決策を生み出します。
そもそも何が問題なのかを明らかにするだとか、最適な解決策を見つけるのが、仕事をしていて一番面白いところだと僕は思っている。
仕事の定義を
理想の状態になることを阻害している問題を見つけて,
問題を解決する手段を考え,解決すること
と 以前書いたことがある。
機能やサービスを開発する過程で出てくる課題を、よりクリエイティブに解決するのは、全能感が出て気持ちいい。
新しいアイディアやアプローチを考えて実際のプロジェクトに取り入れていくのも、テクノロジーやテクニックの進歩によってより良い状態に辿り着いていると思う。
常に新しい方法を模索する姿勢は、成長や、自己実現の欲求に効く。自分のアイディアを形にする体験、形にしたものに対してユーザーからフィードバックを受ける体験が、僕らがプログラマになった原体験だろう。
中腹じゃなく頂上に立てってヤツかなぁ。
広い視野があると、各タスクや機能がどう全体と連動しているのかを理解できる。理解から、より価値に対して効率的な進め方を模索できる。自分のタスクだけでなく他のメンバーの作業状況も見えるので、全体の流れをスムーズにすることを考えられる。戦略ゲームのプレイヤーの位置で日々暮らしたいという欲求と思う。
複雑な状況というのは、クネビンフレームワークで言うところの複雑《Complex》。問題が何なのかが明らかになっていない状態。現代のソフトウェア開発は概ねこの状態からスタートすると考えている。(Chaotic な状態だとタスクフォース的に急いで何かを手を打つだろう、Complicated な状態はもうやるだけになっている (やるだけ距離 がまだ遠いことはある) ので、マネージではなくコントロールして着地に向かうプロジェクトだろう)
何をやるのかを明らかにして、やるだけな状態に持って行くには、分かったことを積み重ねて、仮説を立て、対策していくというアプローチが効く。つまり OODA ループ。観測して (observe)、方向付けて (orient) 、意思決定し (decide)、実行する (act)。実験や試行錯誤を通じて何が効果的であるかを見つける楽しさがここにある。
やるだけになっているものを進めるのでも十分難しいとは思うが、誰も明らかにできていなかった問題に対して自分が輪郭を削り出すことに成功するのは最高に気持ちいい。モデル化に成功すると人類の叡智が一歩前に進んだ気持ちになる。同じ問題には同じ対策が効く。
組織目標はだいたい複雑な状況であるので、複雑な状況を任せられるようになると関与度が上がっていく。
抽象的な要件を具体的なシステム設計や実行計画に変換するのは、とてもクリエイティブな楽しさがある。また、この過程で新しい技術やツール、プロセスを取り入れる機会をねじ込み、自分やチームの経験領域を広げることができる。
目標や成果物を明らかにし、それを達成するための戦略やアプローチを定義するプロセスは、戦略的な思考を活かすことができ、自己効力感がある。
単なるメモなのでまとめも何もないが。
仕事をする上で、何らかのクリエイティブな取り組みがなかったらつまらないと思う。僕はこういう仕事をやりたいし、みんながこういう仕事をやれる (ように経験資源を配れる) 状態だといいなと思っています。
このエントリは HatenaBlog Workflows Boilerplate を用いて GitHub から publish しました。push したら公開されるのは個人でも便利。